
Mi ha sempre affascinato tutto quanto riguarda la branca del machine learning che prende il nome di Natural Language Processing, o NLP.
Dall’avvento di chatGPT, ma soprattutto, da quando sono disponibili diversi modelli di LLM pre-addestrati ed open source e le relative interfacce che ne permettono l’utilizzo, ad esempio GPT4All, ollama e Hugging Face, ho fantasticato, in più occasioni, su come avrei potuto utilizzarli all’interno di un Workflow di KNIME.
In particolare, fin dall’inizio, sono stato polarizzato sull’uso di LLM locali, per diversi motivi:
- mantenere la privacy dei documenti
- controllare interamente il processo
- last, but not least, non spendere nulla per poter effettuare i miei esperimenti
In KNIME, qualcuno avrà percepito le mie elucubrazioni e dalla versione di KNIME Analytics Platform 5.1 è possibile utilizzare un LLM locale o proprietario grazie all’ aggiunta di nuovi specifici nodi.
Usare un LLM per la Sentiment Analysis
L’idea è stata quella di usare un LLM (locale ma anche remoto, poi vedremo) per analizzare il sentiment di alcune frasi, con l’obiettivo di costruire un Workflow che, cambiando i dati in ingresso, potesse, poi, eseguire questo compito su qualsiasi nuovo input.
Per provare questa idea, sono partito da un dataset molto noto, il Large Movie Review Dataset, disponibile su Internet al link https://ai.stanford.edu/~amaas/data/sentiment/.
Si tratta di un dataset di recensioni di films, in lingua inglese, estrapolata dal sito imdb.com.
In questo dataset, le recensioni sono già etichettate col relativo sentiment (positive/negative), ciò mi ha permesso di confrontare l’accuratezza delle risposte dei modelli LLM, come si vedrà nel seguito.
Utilizzare un LLM in KNIME Analytics Platform
Per utilizzare gli LLM locali, KNIME Analytics Platform mette a disposizione, tra gli altri, i seguenti nodi:
Chi conosce e utilizza KNIME Analytics Platform, si meraviglierà di trovare l’ultimo nodo elencato, anche perché era già presente nelle versioni precedenti e non parrebbe entrarci nulla con gli LLM.
In realtà, questo mi ha permesso di usare ollama, un applicativo che gira su Linux come un servizio, tramite cui è possibile selezionare un modello LLM da una lista abbastanza nutrita, inviare una richiesta alla porta :11434 del localhost, in formato JSON, che includa il prompt e prelevare la risposta.
Per poterlo utilizzare in ambiente Windows ci sono diversi modi, ad esempio installando un’istanza di ollama in container tramite docker, o meglio ancora, utilizzando la possibilità di avere un’istanza di Linux funzionante in Windows tramite il WSL. In Linux o sotto WSL, ollama si installa col comando curl https://ollama.ai/install.sh | sh, niente di più facile.
Il Workflow sviluppato usando KNIME Analytics Platform
Con tutti questi ingredienti, quindi, ho creato il Workflow sottostante:
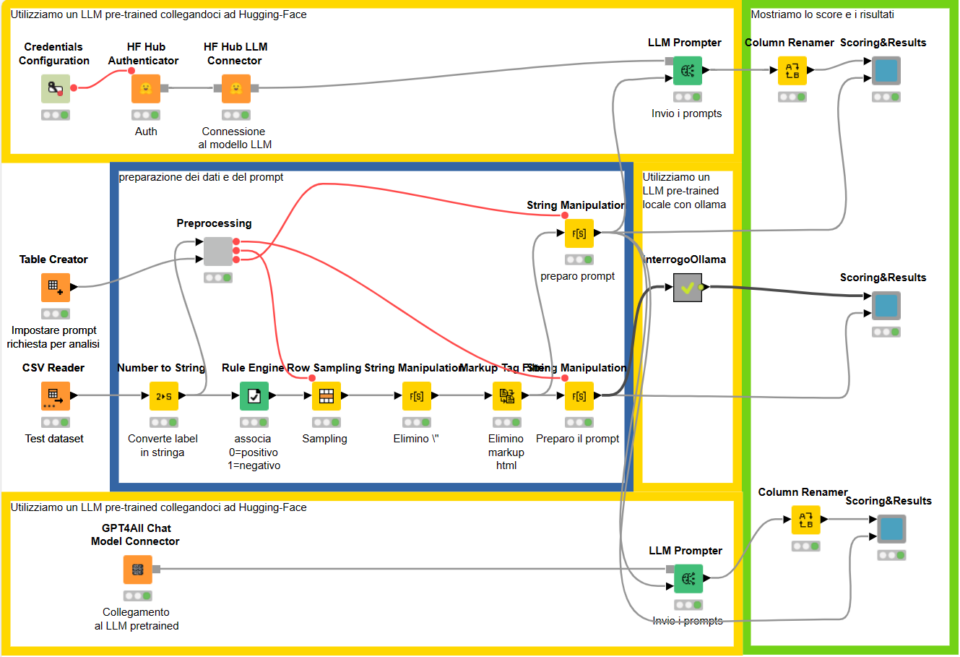
Come si può vedere, sul lato sinistro prelevo le sentences dal dataset IMDBs che ho preventivamente scaricato, mentre nelle diramazioni che seguono utilizzo, in ordine:
- Un LLM (Zephir) di Hugging Face, interrogandolo remotamente
- Un LLM locale (openchat) con ollama, interrogandolo tramite REST
- Un LLM locale (openorca) tramite il nodo GPT4All.
Per effettuare le mie prove ho utilizzato un campione ridotto ma bilanciato di sentences, estraendole a caso dal dataset originale, che ne contava più di 5000 (anche questo è un subset, perché il dataset nativo ne ha molte di più).
I risultati tramite Score
Anche se il campione era molto ridotto, i risultati sono stati eccellenti:
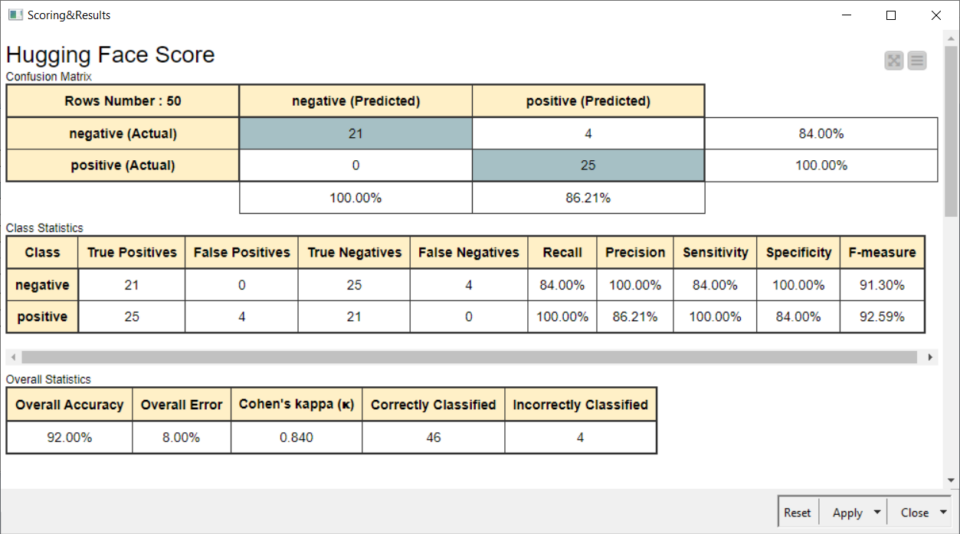
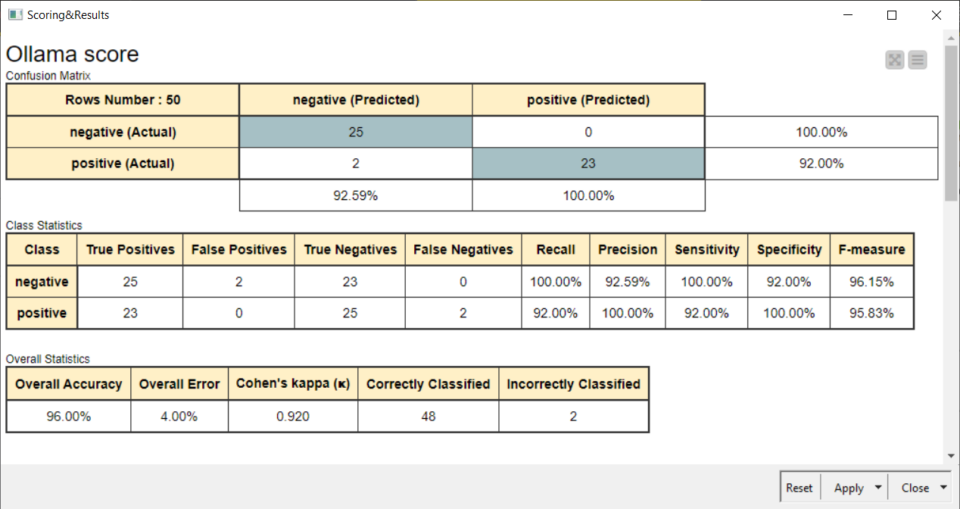
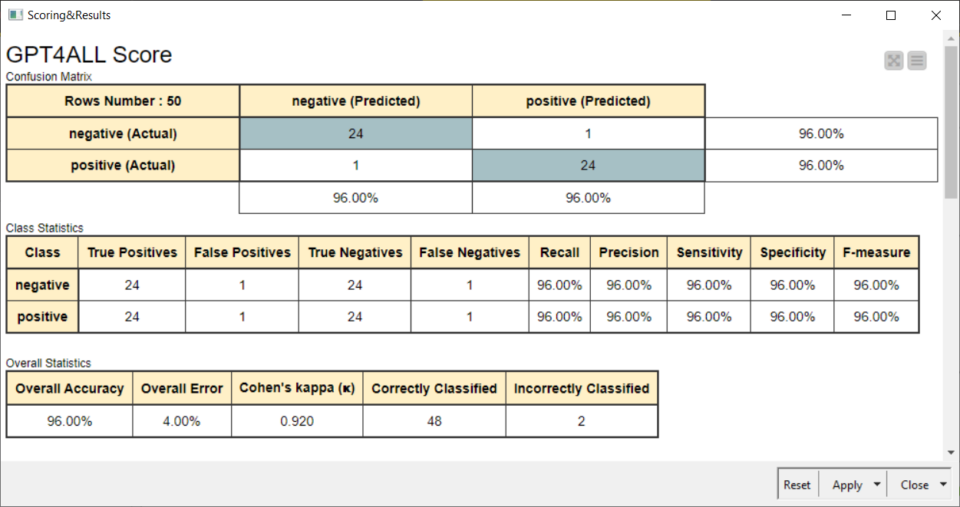
Limiti dell’utilizzo di LLM locali e conclusioni
Unico inconveniente è che, a parte Hugging Face, che ha fornito le risposte molto velocemente, l’utilizzo degli LLM locali ha richiesto parecchio tempo (anche un’ora) e, inoltre, sono soluzioni che utilizzano molta RAM, per cui sono inutilizzabili in macchine con meno di 16GB, ma per il resto, come pensavo, si prestano in maniera eccellente a sostituire altri metodi di machine learning, pure validi ma comunque più complessi.
Spero che questi sistemi di LLM locale, col tempo, evolvano ulteriormente permettendo di ottenere prestazioni migliori a parità di risorse elaborative, perché si prestano molto bene ad essere utilizzati per l’NLP, dato che alcune attività a questo collegate, sono nativamente disponibili all’interno delle abilità di LLM anche piccoli.
Se volete imparare KNIME Analytics Platform, potete acquistare uno dei miei corsi su Udemy:
KNIME Analytics Platform per data scientists, corso base
KNIME Analytics Platform per data scientists, intermediate
Il coupon da utilizzare per acquistarli al costo di 12,99€ (cadauno) è: DSFACILE2404